ETL library by Raynet has the following principles:
•Cross-platform (works on Windows, UNIX, Docker etc.)
•Independent from data source (currently supports MS SQL, but is platform-agnostic in its core. Future implementations will include SQlite, MariaDB, OracleDB, REST etc.)
•Secure (all operations happen in a sandbox)
•Transparent (instead of large, complex operations, the work is split to smaller units of work)
•Efficient (works with data sets having several terabytes of sizes)
•Portable (has no dependencies to any DB and other frameworks, except of the data that is extracted from source and loaded to the target)
•Configurable (all operations are defined in JSON format, no direct SQL involved)
•Flexible and easy to change (complex operations are abstracted, so that typical tasks can be achieved with a single change, without writing complex join or other queries).
To achieve this, the following is involved:
•The user defines his transformation processes in a JSON file with a specified syntax. This JSON file can be crafted by hand or by using some visual editing tools that Raynet provides in the future (see section tooling).
•The transformation layer performs extraction by reading out the necessary tables that the user required. It then copies these tables from the data source (with help of specific data adapter) to a sandbox environment, utilizing embedded temporary SQLite database.
•The transformation is performed in the SQLLite database and has no access to the original data source. All steps can see only the tables that were referenced by the user.
•Once the transformation is done, the tables from the sandbox are copied back to the target environment, again using specific data adapter.
The operations executed in each step may be executed either directly in the sandbox (native SQLLite query) or in memory. The engine tries to rely as much as possible to the sandbox database engine, which is usually the fastest way of transforming, filtering etc. Using certain features provided by the engine may transparently switch to in-memory execution, which may involve small performance hit.
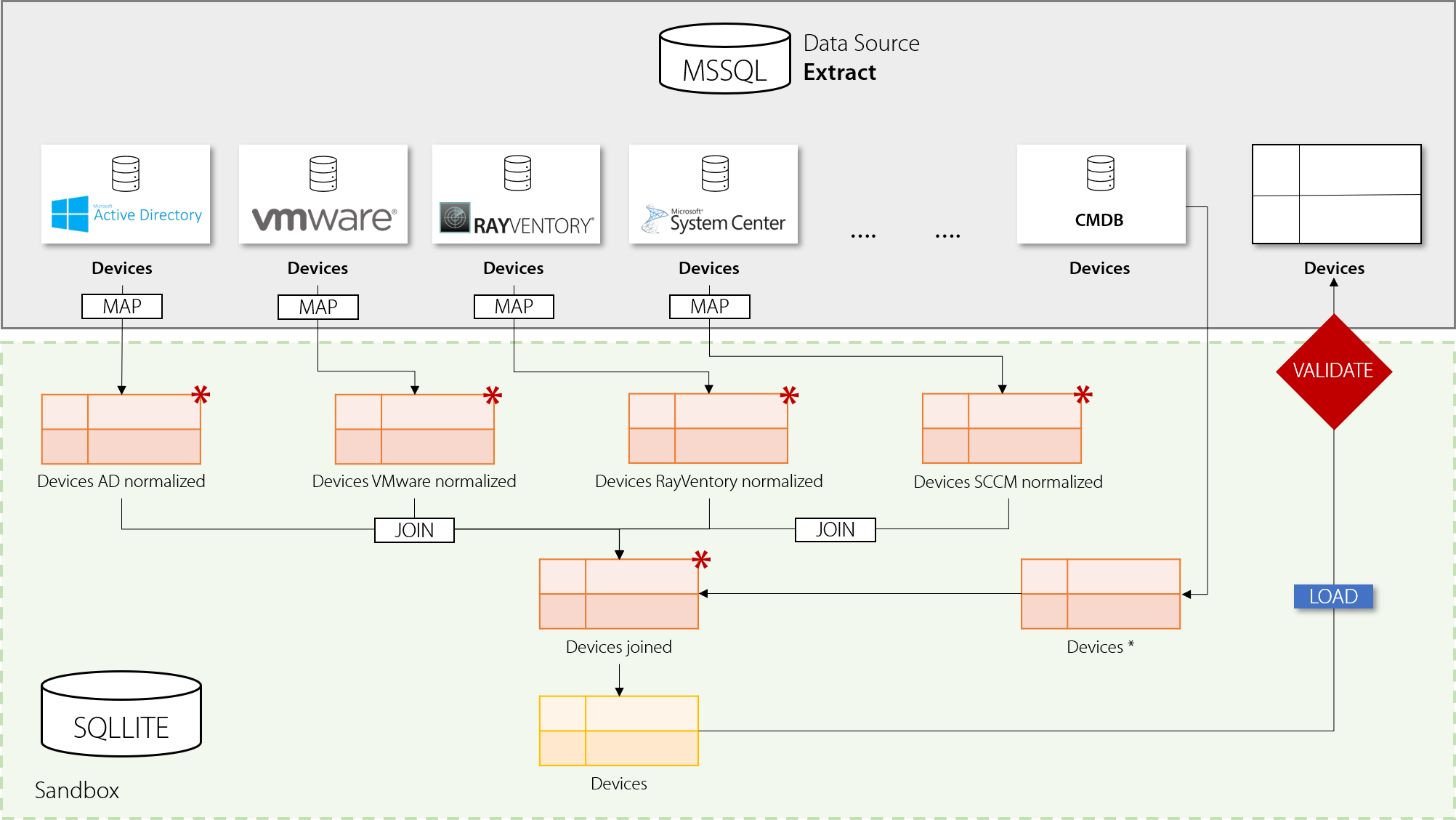
At the end, data validation should happen on the RayVentory Data Hub site, to ensure that the tables are correct from the business point of view (all columns, required names, non-null fields etc.). This does not belong to the scope of ETL library from Raynet.
The operation that happen in the sandbox may be parallelized. By default, the library tries to create a graph of dependencies and execute tasks in batches, if all dependencies are fulfilled. In the example above, first four tasks DevicesAD_Normalized, DevicesVmware_Normalized, DevicesRayVentory_Normalized and DevicesSCCM_Normalized have only dependencies to the source DB (and no other steps), so they may be executed in parallel. On the other hand, there are some other steps that depend on these four, so the other steps will wait until all four are executed.