In order to transform the data (Transform), we need to plug-in some initial raw or partially transformed data (Extract), and the after processing load it back to the data source (Load).

Transformation step should be understood as a process of one or more steps, which may be interconnected, with many inputs and many outputs. The following steps are currently available:
•Map
Transforms one table to another table. Mapping can take existing columns as-is, rename them, perform simple or complex transforming, aggregating or disaggregating them etc. The result table has always as many rows as the input table, but the number of columns may be different.
•Filter
Takes the input table and filter out items that do not match a specific set of conditions. The result table has always the same number of columns, but may have a different number of rows, depending on the filtering.
•Join
Joins two or more tables together by combining columns with the same names, using specific methods of aggregation. The input are two or more tables, and the output is a single table.
•Deduplicate
Based on unique value of one or more columns, this steps deduplicates the table based on the conditions defined by the user.
•Enrich
Adds information to a specific column of a source table by performing a look-up in another table(s) using set of ordered look-up rules. The input is a single table + a set of look-up tables, the output is a single table with all the columns from the source table + the enriched column if it was not present in the original table.
These steps can be used to perform complex operations by splitting big unit of works into smaller bits, that are building blocks for the complex transformation.
This sample advanced process may have the following workflow:
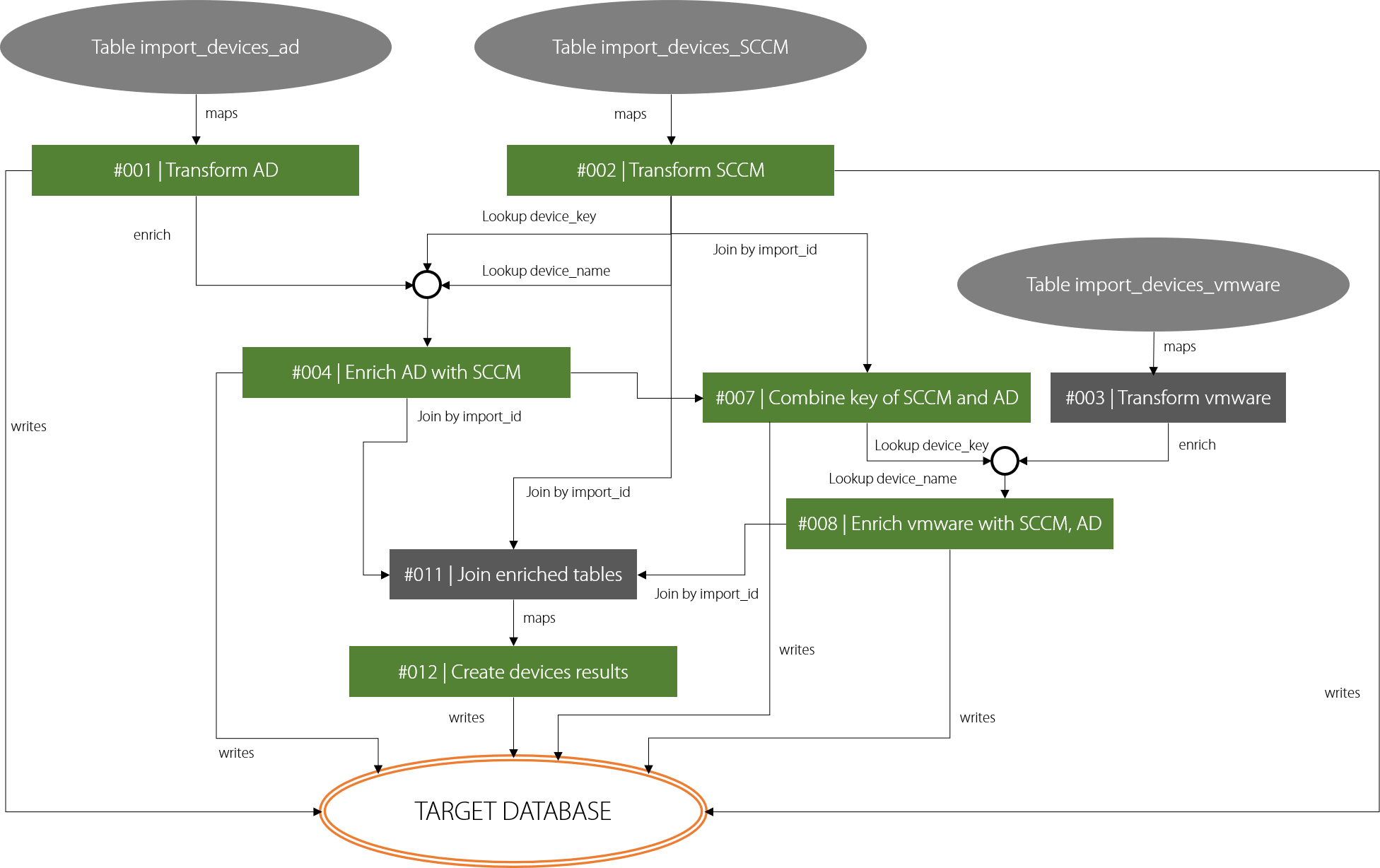
Transformation process is a chunk of steps which perform a given task (for example: take Active Directory, RayVentory and Vmware source raw data and produce a single table combining the sources together). Obviously, there may be more independent ETL processes defined for a single data set.
As pictured above, a single step (for example a single mapping or joining) can have different number of sources, and itself it may be a source for one or more steps.
The results of each step is by default temporary that means it will not be written to the target database. To mark a step as “result”, the user must do it explicitly. In the chart above, all “green” steps are written to the target database, but the gray ones (#011 and #003) are not and exist only as intermediary steps for other steps.
An output of a step if always a single table, which can be temporary or permanent (written back to the database). However, it is important not to confuse the step with the table. Each step is an operation on the data, which has inputs and output, and the output of the step is a table.