Grouping is process which covers the following use cases:
•When having a single table, it writes an output table that has the exact amount of rows but with extra meta-columns containing a "group identifier". Two or more elements considered to be the same have always the same value in the group column. The second extra column being added is the count of rows in the given group.
•When having a single table, it writes an output table that contains aggregated (deduplicated / distinct) rows, where the values in each non-grouped colum is aggregated with a specific function (maximum, minimum, average, concatenated value, coalesced value). An extra column with a number of grouped rows is added.
The following snippet shows a functional example required to group rows and enter the information about the group:
{ "id": 1, "type": "group", "name": "Example of grouping (deduplicate)", "source": "Users", "by": [ "Name", "E-Mail" ], "target": "Users_Grouped_Deduplicated" } |
It is possible to opt-in for deduplication by using the "action" object:
{ "id": 2, "type": "group", "name": "Example of grouping (deduplicate)", "source": "Users", "by": [ "Name", "E-Mail" ], "target": "Users_Grouped_Deduplicated", "action": { "type": "deduplicate" } } |
Required properties:
•ID (must be unique)
•Type (must be set to "group")
•Source (must be one of the following):
oA string representing the table name
oAn integer representing the source as another step
oAn object with the property "table" set to the name of the source table
oAn object with the property "step" set to the ID of the source step
Source is by default optional which means that the table does not have to be existing. IF the table is missing, the step will not be executed and its target table will not be written. There is a way to define that the source is required, in which case in case of a missing source table, the step will fail and report an error. More information about the setup of the required steps can be found in the ETL Implementation Guide.
Optional parameters:
•by: This defines a single column or a list of columns to be used as grouping keys. Equivalent to the SQL statement SELECT * FROM <table> GROUP BY <columns>.
If this parameter is omitted or set to an empty list, then all columns are used for grouping.
•target: If omitted, the output table is temporary and does not get saved during the LOAD phase.
•action: The action to execute. This can be one of the following:
oIf the value is a string, then the action of a given type is used. Supported values are deduplicate and recognize. The values are case-insensitive.
oIf the value is an object, then its property type is used to determine the action. The value of the parameter type should be either deduplicate or recognize. The values are case-insensitive. There are some extra properties available when using the object syntax.
oIf the action is omitted, the recognize action is used as the default.
Configure Group in Raynet One Data Hub
Recognize

•SOURCE TABLE: Enter the table that is used as source for the data. It supports auto-completion and will offer all available tables matching the current input string.
•GROUP BY: Enter the column names that will be used to group the data. The field supports auto completion and will offer all available columns matching the current input string. The columns will be separated by commas.
•GROUP TYPE ACTION: This field is used to select the Group Type Action that will be used. The available options are Recognize and Deduplicate. The following entries represents the fields that are available if Recognize is chosen. For the fields available if Deduplicate is chosen see further below.
•COLUMN NAME OF GROUP KEY: This field is used to customize the column name of the group key. By default, the name used for the column is GROUP_KEY.
•COLUMN NAME OF GROUP COUNT: This field is used to customize the column name of the group count. By default, the name used for the column is GROUP_COUNT.
Deduplicate
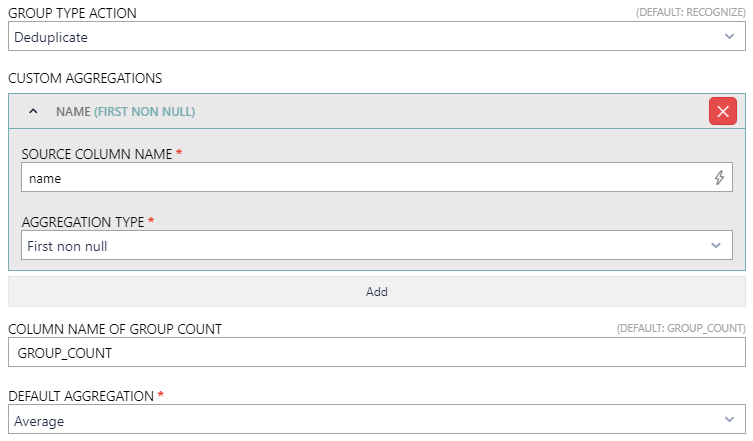
•GROUP TYPE ACTION: This field is used to select the Group Type Action that will be used. The available options are Recognize and Deduplicate. The following entries represents the fields that are available if Deduplicate is chosen. For the fields available if Recognize is chosen refer to the previous section.
•CUSTOM AGGREGATIONS: This can be used to add additional customized aggregations to the transformation.
oSOURCE COLUMN NAME: Enter the column from which the value will be taken. It supports auto-completion and will offer all available columns matching the current input string for selection.
oAGGREGATION TYPE: Define the method that will be used to produce a single value out of the input values by selecting the aggregation type from the dropdown menu. The following options are available.
▪Average: Selects the average value of one or more values.
▪Coalesce: Selects the first not-empty value from the list of one or more values.
▪Concat: Join all given non-empty values using a specific separator (from left to right).
▪First non null: Selects the first not-empty value from the list of one or more values.
▪Maximum: Selects the maximum of one or more values.
▪Minimum: Selects the minimum of one or more values.
▪Sum: Selects the sum of one or more values.
•COLUMN NAME OF GROUP COUNT: This field is used to customize the column name of the group count. By default, the name used for the column is GROUP_COUNT.
•DEFAULT AGGREGATION: Define the method that will be used to produce a single value out of the input values by default by selecting the aggregation type from the dropdown menu. The following options are available.
▪Average: Selects the average value of one or more values.
▪Maximum: Selects the maximum of one or more values.
▪Minimum: Selects the minimum of one or more values.
▪Sum: Selects the sum of one or more values.
▪Coalesce: Selects the first not-empty value from the list of one or more values.
▪Concat: Join all given non-empty values using a specific separator (from left to right).
▪First non null: Selects the first not-empty value from the list of one or more values.